
Python覚書き
データ型・変数・演算子
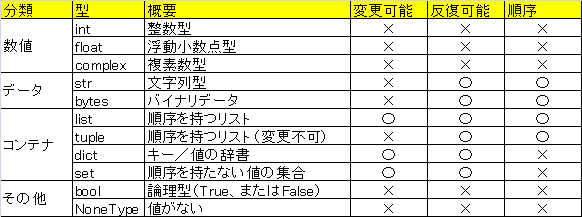
●ミュータブル(mutable):変更可能
●イミュータブル(immutable):変更不可
●イテラブル(iterable):反復可能
●シーケンス(sequence):順序を持つ(インデックスでのアクセスが可能)
●コンテナ(container):配下に複数の値を格納可能
●アンパック代入(一部の要素を切り捨てる)
test = [1, 2, 3, 4, 5]
a, _, b, _, c = test
print(a) #出力結果:1
print(b) #出力結果:3
print(c) #出力結果:5
print(_) #出力結果:4●アンパック代入(入れ子のリスト)
test = [1, 2, [55, 56, 57]]
a, b, c = test
print(a) #出力結果:1
print(b) #出力結果:2
print(c) #出力結果:[55, 56, 57]
x, y, (z1, z2, z3) = test
print(x) #出力結果:1
print(y) #出力結果:2
print(z1) #出力結果:55
print(z2) #出力結果:56
print(z3) #出力結果:57●変数値のスワッピング(入れ替え)
x = 88
y = 99
x, y = y, x
print(x, y) #出力結果:99 88●Python3.8からの代入演算子「:=」
y = (x = 20) / 10 #Python3.7以前ではこの様な式は記述できなかったが・・・
y = (x := 20) / 10 #Python3.8では「:=」を使用する事で可能となった
エスケープシーケンス
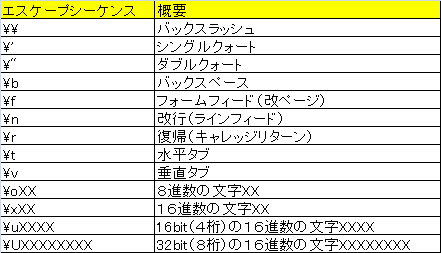
●raw文字列(文字列の前に「r」付加)表記のままに解釈する文字列リテラル
例 print(r’C:\Program Files\MikuMikuDance\Data’)
●フォーマット文字列(文字列の前に「f」付加)文字列中に変数を埋め込み
toho = “魔理沙"
print(f’ゆっくり{toho}’) #出力結果は「ゆっくり魔理沙」
制御構文
●処理がない場合は「pass」を記述する
if x == 21:
pass●多岐分岐(elif)Pythonは「switch」命令なし
toho = "霊夢"
if toho == "魔理沙":
print("ゆっくり魔理沙")
elif toho == "チルノ":
print("ゆっくりチルノ")
else:
print("ゆっくり霊夢")●for文(インクリメント)
for i in range(1, 4): # 1 ~ 3
print(i)●range関数
#0からN未満
range(N)
#増分指定
range(0, 10, 2) #出力結果:[0, 2, 4, 6, 8]
#減分指定
range(5, 0, -1) #出力結果:[5, 4, 3, 2, 1]
reversed(range(0, 10, 2)) #出力結果:「8, 6, 4, 2, 0」
#リスト化
print(list(range(0, 5, 2))) #出力結果:[0, 2, 4]●リスト内包表記
#2倍
data = [15, 43, 7, 59, 98]
data2 = [i * 2 for i in data]
print(data2) #出力結果:[30, 86, 14, 118, 196]
#文字変換
data3 = [str(i) for i in data]
print(data3) #出力結果:['15', '43', '7', '59', '98']
#条件指定
data4 = sum([i for i in data if i < 50])
print(data4) #出力結果:65例外処理
try:
TypeError('エラーです')
except (ValueError, TypeError) as ex:
print('エラー指定')
else:
print('エラー発生なし')
finally:
print('必ず通る')標準ライブラリ
●文字列の長さを取得する(文字数)len
toho = 'ゆっくり霊夢'
print(len(toho)) #出力結果:6●文字列の長さを取得する(バイト数)unicodedata.east_asian_width(…)
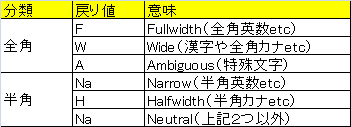
import unicodedata
test = 'ゆっくりMarisa'
mojisu = 0
for ch in test
if unicodedata.east_asian_width(ch) in 'FWA':
mojisu += 2
else:
mojisu += 1
print(mojisu) #出力結果:14●大文字・小文字変換

test1 = 'Yukuri Marisa'
test2 = 'yukuri reimu hakurei'
print(test1.lower()) #出力結果:yukuri marisa
print(test1.upper()) #出力結果:YUKURI MARISA
print(test1.swapcase()) #出力結果:yUKURI mARISA
print(test2.capitalize()) #出力結果:Yukuri reimu hakurei
print(test2.title()) #出力結果:Yukuri Reimu Hakurei●部分文字列
test = 'あいうえおかきくけこ'
print(test[2]) #出力結果:う
print(test[2:5]) #出力結果:うえお
print(test[2:]) #出力結果:うえおかきくけこ
print(test[:5]) #出力結果:あいうえお
print(test[:]) #出力結果:あいうえおかきくけこ
print(test[-7:]) #出力結果:えおかきくけこ
print(test[-7:-5]) #出力結果:えお
print(test[::2]) #出力結果:あうおきけ 0文字目を基点に2文字おきに取得
print(test[1::2]) #出力結果:いえかくこ 1文字目を基点に2文字おきに取得
print(test[::-1]) #出力結果:こけくきかおえういあ stepに負数 逆順